Cross-Validation of your models#
One of the things about machine learning is that it often leverages randomness (sampling, shuffling, etc) to build the strength in your claims. We can use this to our advantage by being able to estimate the performance of model. Below we show how to do this using “Monte Carlo” methods, i.e., simple bootstrapping.
The sci-kit library has many buiult-in tools for validation, which you will emply at the end on your own.
from sklearn.datasets import make_regression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
#conda install -c conda-forge seaborn (you might need to run this first)
import seaborn as sns
Generate some regression data and store it in a data frame#
# Generate regression dataset with 10 variables
X, y = make_regression(n_samples=1000, n_features=20, n_informative=3, noise=10)
# Convert the data set to a Pandas dataframe
df = pd.DataFrame(X)
df['response'] = y
Plot the features#
Note this takes a while to run. You don’t have to use it everytime
# Create a scatter plot of the features
pd.plotting.scatter_matrix(df, figsize=(12,12), diagonal='kde')
plt.show()
Make our process modular#
One of the useful things about the sci-kit library is that it makes the process of doing machine learning pretty routine. In that we know the process that we follow and we can find where in the process to diagnose issues. This is not to say any of this is simple, but rather it can be made into a process.
Below, we’ve written a function that performs a linear regression on data. It returns the Mean Sqaured Error (mse), the R\(^2\) value (r2), and the fit coefficients for the linear model (coeffs). Notice this last variable is a list not just a number. It will be as long as the number of features in the model.
def linear_regression(X, y, testSize=0.2):
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testSize)
# Create a linear regression model
lr = LinearRegression()
# Fit the model with the training data
lr.fit(X_train, y_train)
# Predict the target variable using the test data
y_pred = lr.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
r2 = lr.score(X_test, y_test)
coeffs = lr.coef_
return mse, r2, coeffs
Call our function#
Now, we can call our function a notice that it produces a differnt value each time because it is randomly sampling every time it runs.
mse, r2, coeffs = linear_regression(X,y)
print('MSE: ', mse)
print('R2: ', r2)
print('Fit Coefficients:\n', coeffs)
MSE: 109.41294094314388
R2: 0.9814356782745867
Fit Coefficients:
[ 2.57364203e-01 3.03216912e-01 -5.07373722e-02 6.28638910e-01
3.66093765e+01 1.16250765e-01 9.09160594e-01 -3.77170272e-01
-1.74660765e-01 1.60609549e-02 -2.41841966e-01 6.70387935e+01
2.68687408e+01 -3.27815341e-01 6.48999019e-02 -1.22394507e+00
9.58183323e-01 5.99739022e-01 1.78151955e-01 -5.62013864e-02]
mse, r2, coeffs = linear_regression(X,y)
print('MSE: ', mse)
print('R2: ', r2)
print('Fit Coefficients:\n', coeffs)
MSE: 103.34059285868153
R2: 0.9825889606325889
Fit Coefficients:
[-7.74836721e-02 5.07102955e-01 7.28559030e-02 7.68380074e-01
3.66602208e+01 1.00979635e-01 8.43682070e-01 -4.52820120e-01
-9.33171628e-02 -1.73849839e-01 -2.49958025e-01 6.68468456e+01
2.69126403e+01 -4.26747644e-01 2.33083487e-01 -1.16324122e+00
5.55558171e-01 5.33149738e-01 -1.09090538e-02 -1.26103807e-01]
Automating the runs#
Now that we have this working, we can run a loop a perform as many of these analyses as we like. Below, we’ve written a short loop that does this and stores all the important things a pandas data frame for later.
Nruns = 100
arr = np.arange(1,Nruns+1)
# Initialize an empty list to store the DataFrame of each run
dfs = []
for i in arr:
# Run the linear regression function
mse, r2, coeffs = linear_regression(X, y)
# Create a DataFrame for this run
df = pd.DataFrame({'Run': i, 'MSE': mse, 'R2': r2, 'Coeffs': [coeffs]})
# Append the DataFrame to the list of all runs
dfs.append(df)
# Concatenate all DataFrames into a single DataFrame
results_df = pd.concat(dfs, ignore_index=True)
# Print the results DataFrame
#print(results_df)
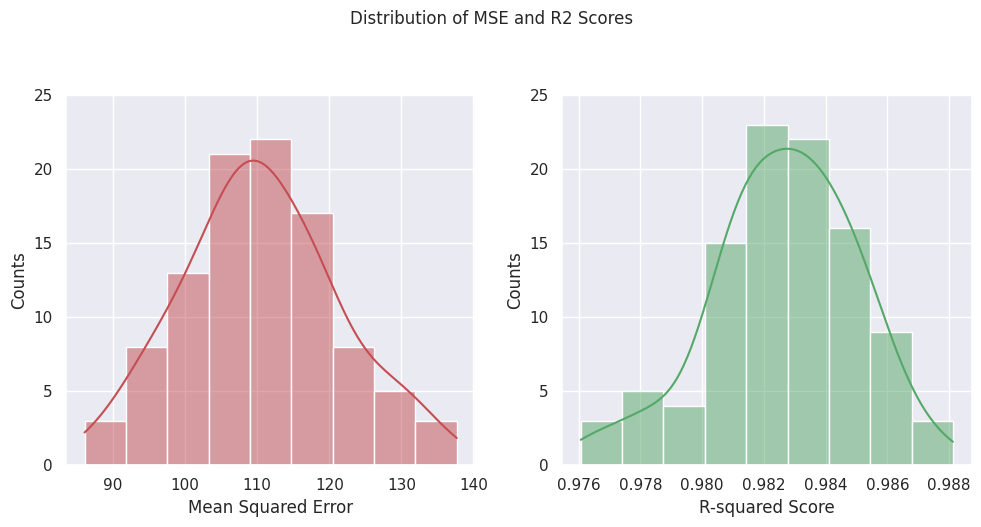
Plot the distributions#
Below, we plot the distributions of the results, which demonstrate both the random nature of the train/test splitting, but also that we can build confidence in our analysis by providing uncertainty to our estimates.
### Plotting MSE and R2
sns.set(style='darkgrid')
# Plot a pair of histograms for the MSE and R2 scores
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
sns.histplot(results_df['MSE'], ax=ax[0], kde=True, color='r', edgecolor='w')
sns.histplot(results_df['R2'], ax=ax[1], kde=True, color='g', edgecolor='w')
# Set the axis labels and titles
ax[0].set_xlabel('Mean Squared Error')
ax[1].set_xlabel('R-squared Score')
ax[0].set_ylabel('Counts')
ax[1].set_ylabel('Counts')
# Change the y-tick marks
yticks = [0, 5, 10, 15, 20, 25]
ax[0].set_yticks(yticks)
ax[1].set_yticks(yticks)
plt.suptitle('Distribution of MSE and R2 Scores', fontsize=12, y=1.05)
plt.tight_layout()
plt.show()
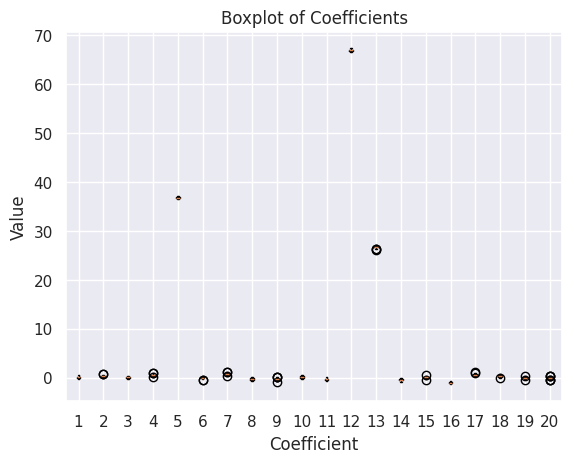
### Plotting Fit Coefficients
coeffs_data = []
for run in results_df['Coeffs']:
coeffs_data.append(run)
num_coeffs = len(coeffs_data[0])
positions = range(1, num_coeffs + 1)
for i in range(num_coeffs):
# Extract coefficients
coefficient_data = []
for run in coeffs_data:
coefficient_data.append(run[i])
# Create boxplot
plt.boxplot(coefficient_data, positions=[positions[i]])
plt.xlabel('Coefficient')
plt.ylabel('Value')
plt.title('Boxplot of Coefficients')
plt.xticks(positions, range(1, num_coeffs + 1))
plt.show()
Things to try#
We have performed “Monte Carlo” validation where we randomly sample the training and test sets. The sci-kit library has forms of validation built-in. You can find lots of details on their documentation. Here’s a bit more on how each validator selects data.
Review the
sci-kitdocumentation and reproduce our work above using a built-in validator.Change the training and testing sizes, how well does your model perform?